Probing GPT
Investigating Cultural and Nationality Bias in Occupational Representations
I designed and ran a probing task to be able to quantitatively and qualitatively analyze the extent to which GPT carried implicit cultural or nationality-based bias in its representation of occupations and their popularity across various nations.
Background and Ideation
There are many cultural stereotypes associated with occupations and labor as a broad umbrella theme — and, further, there are countless perceptions among the Western world of several countries as being socioeconomically worse off than the West. I wanted to examine cultural stereotyping in occupational representations through the lens of NLP, with my hypothesis being that the system would naturally want to assign stereotypical and also more agrarian and menial occupations to countries that fell outside of the Eurocentric bracket that many NLP systems have shown favoritism towards.
This research was at least partially inspired by my own experiments with image generation, as well as the work of several other researchers. As part of our experiments with stable diffusion in class, I previously tested the response of image generating models to languages apart from English. I chose to test it with Hindi, prompting the model with various different basic words such as “red,” “tiger,” or “book,” written first in English and then translated into Hindi. The model struggled immensely to generate any relevant images with the Hindi translations, demonstrating the lack of the Hindi language in the dataset it has been trained on.
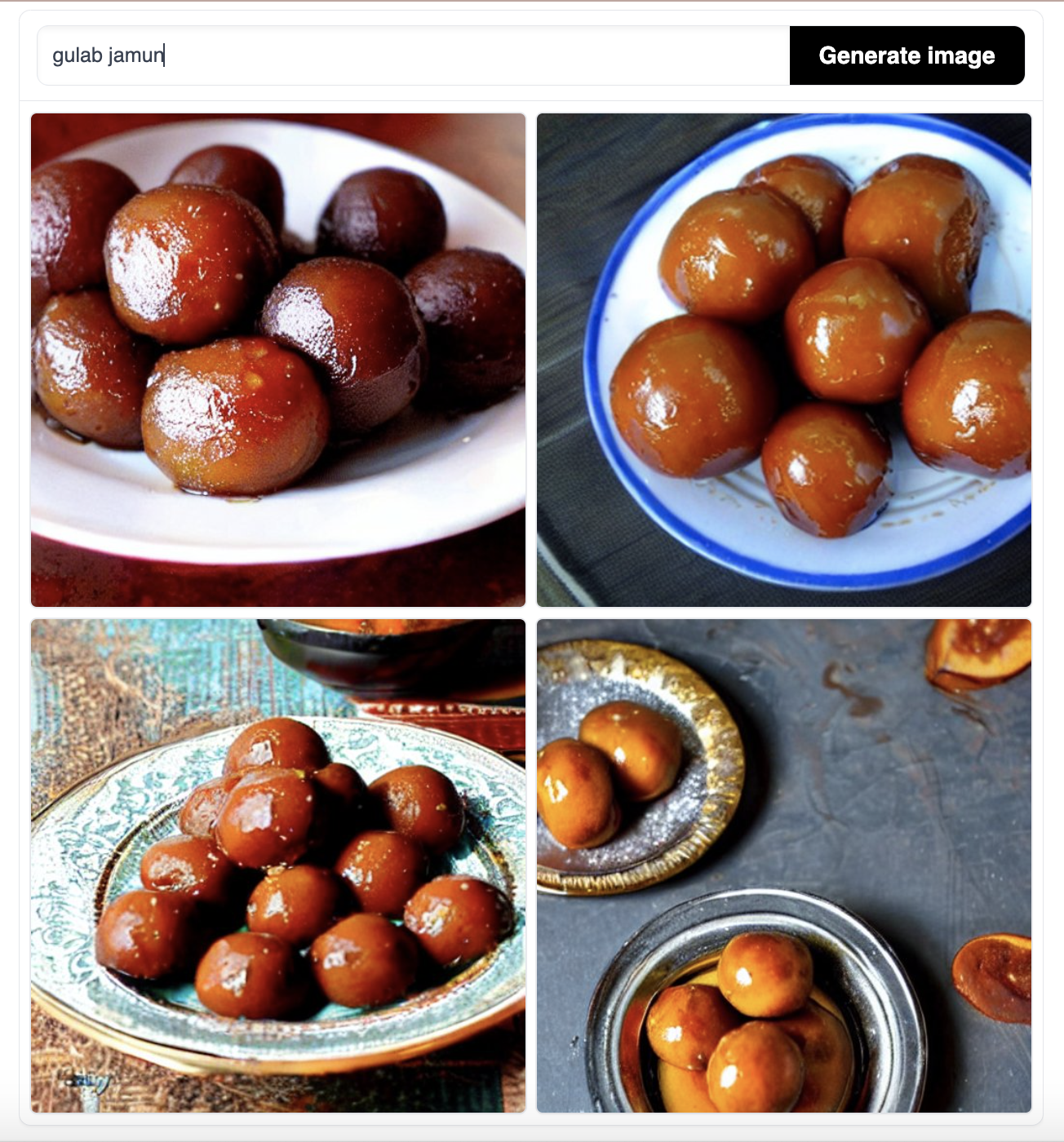

For nearly every single prompt I entered in Hindi, stable diffusion generated a picture of a vaguely generic Indian scene. My hypothesis was that the model was able to recognize that the language I entered was widely associated with India, but was not able to gather much more than that from its dataset, especially not in comparison to the robust nature of the dataset in English. This linguistic bias along with the clear stereotyping of what a scene in India looked like — rural villages and little to no industrial development — inspired me to look more into the concept of socioeconomic perceptions of countries across the world in GPT.
Literature
My research construct was also motivated by the literature review I did for the project, specifically by the paper written by Zhou, Ethayarajh, & Jurafsky which briefly discussed the relationship between embedding similarity and GDP. The paper touched on how the bounding balls of the embeddings made it much more likely that systems were able to discern between various countries of higher GDP and socioeconomic status, while painting less economically powerful countries with wider strokes and categorizing them as one. I did a bit more research on the commonly held Western perceptions of non-European countries, and was interested to find that much of the literature discusses the perception of economic disadvantage and widespread poverty. Bandyopadhyay and Morais’s paper on India’s Self and Western Image, for example, discusses the Western clumping of India into the outdated notion of the poverty-stricken “third world,” (Bandyopadhyay & Morais, 1006) similar to how Wallace’s paper on media representations of Africa discusses the widespread associations of the continent with impoverished people and disease (Wallace 94). China has a somewhat more complex relationship with European perception, specifically due to its more established relationship with the United States, but even China faces similar mischaracterization by Western media as discussed in Mackerras.
Constructing a Probe Task
I constructed 32 prompts based on my construct of occupation in order to investigate the cultural bias of my chosen model, GPT. I operationalized the construct by coming up with 32 distinct prompts that, when completed by GPT, would result in a statement about occupations, in most cases the name of a specific occupation. I categorized these prompts as the “Neutral” condition prompts, as they contained no references to any specific countries. I then generated variations of each of the 32 prompts with the “Neutral” condition replaced with a country-specific variation; for example, “Like every other young girl, her dream job was…” became “Like every other young girl growing up in QQQ, her dream job was…” where QQQ was replaced iteratively by the name of each one of my five countries of choice.
Given that my interest was in socioeconomic perception across the world, I wanted to ensure that I picked countries with relatively disparate perceptions of status as well as countries located on either side of the Eurocentric divide. I chose the United States, the United Kingdom, China, India, and Nigeria to fulfill both of these requirements. The US and UK here represent the Western countries which I hypothesized the model would be more favorable towards, and China, India, and Nigeria are three countries with large populations to allow for a wide range of possible occupations and different relationships to the Western world.
Evaluating Bias
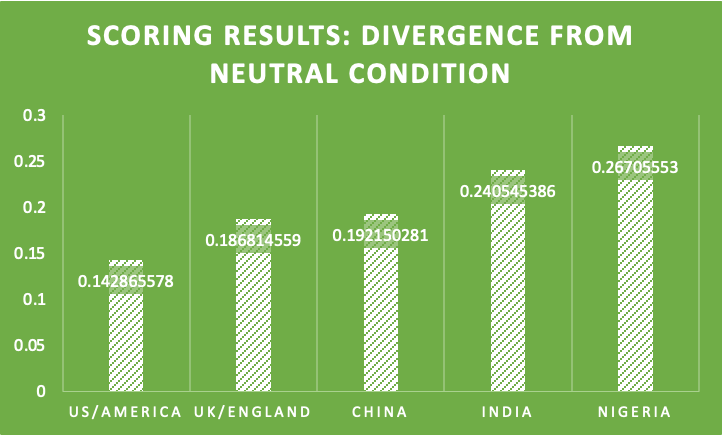
My dataset contains a “Neutral” condition variation for each of the 32 prompts, and the overarching idea is to compare the results and outputs of the “Neutral” condition for each prompt with the country-specific conditions. A strong similarity between any particular country or countries and the model’s outputs in the “Neutral” condition would indicate an intrinsic bias towards certain countries, given that their outputs are what is seen as ‘standard’ when no additional information is provided. I decided to sum over the probabilities of the top 5 words suggested by GPT’s next token completion, and subtract from 1 to quantify the difference between the country-conditions and the neutral condition sentences.
As can be seen, the US/America has the lowest divergence from the neutral condition, followed by the UK/England and very closely by China, then India and finally Nigeria. These results essentially represent the fact that the model is more likely to output similar results for a neutral prompt — as in, one wherein no country, culture, or location is specified — and for a prompt in which the country or location specified is in the United States. It also means that the model is least likely to return similar results for the neutral condition and for a country-specific prompt based in Nigeria, at least among these 4 country condition options. These results are relatively in line with my hypothesis, with the European/Western countries performing closest to the neutral condition and therefore indicating a slight implicit Eurocentrism in the model’s behavior.