Amazon Review Helpfulness
Logistic Regression and Bag of Words
I worked with a partner to create a logistic regression classifier to be able to discern a "helpful" review from an "unhelpful" one, as determined by user helpfulness upvotes. We then used the bag of words approach to determine which words were most and least indicative of helpfulness in a review.
Background and Literature
In our pursuit to understand the intricacies of Amazon.com reviews and their helpfulness, we read several other papers on the topic by researchers spanning many different approaches and time periods.
In 2009, Mizil et al. wrote a paper entitled “How Opinions are Received by Online Communities: A Case Study on Amazon.com Helpfulness Votes,” which considered four different hypotheses for predicting review helpfulness and constructed a framework to determine their validity. One was the brilliant-but-cruel hypothesis predicts that negative reviewers are perceived as more intelligent and competent than positive reviewers and therefore negative reviews are overall perceived as being more helpful. The researchers created a mathematical model based on the notions behind their hypotheses and rejected the brilliant-but-cruel hypothesis based on their findings.
In 2013, Skalicky wrote a paper entitled “Was this analysis helpful? A genre analysis of the Amazon.com discourse community and its “most helpful” product reviews” in which the researcher conducted a study of the rhetorical patterns in helpful and unhelpful reviews. They found a difference in the patterns, and argued that overall, reviews containing experience-based information, as in rhetoric that expanded on a user’s own experiences with the product or service, were more likely to be evaluated as helpful. This is in contrast to reviews containing search-based or quasi-advertisement rhetoric, such as information about the product or service that could be found online or overly positive feedback that invokes the rhetoric of an advertisement, which were less likely to be found helpful.
In 2019, Du et al. conducted a study called “Feature selection for helpfulness prediction of online product reviews: An empirical study” in which they combined all the most popular methods of featurizing the data from various studies involving Amazon.com reviews — for example, number of words, unigrams, etc. — and tested the classification accuracy across all methods. The ‘semantics’ category of featurization was overall, the highest, with specifically unigrams — commonly analyzed via the Bag of Words approach — setting the baseline in all domains. All other semantic analyses variably approached slightly lower or occasionally higher classification accuracy, but unigrams were relatively consistent overall.
Our literature review helped us to identify approaches we wanted to take for our study, as well as patterns in the results we were interested in looking out for. For example, despite the 2009 study’s rejection of the brilliant-but-cruel hypothesis, the 2013 rhetorical study found that ‘advertisement’ and overly positive rhetoric was likely not seen as helpful — which prompted us to question whether the idea of negative reviews being seen as more helpful overall has changed with time, especially given the exponential growth of Amazon and Internet use in general. The 2019 study also helped lead us to choose the Bag of Words approach with unigrams, based on their success and consistency in Du et al.’s analysis.
Data Collection and Model Training
We used the Amazon Review Dataset (Version 2) by Jianmo Ni. Because the full dataset contained over 233 million reviews in total, we arbitrarily selected five smaller subcategories: Amazon Fashion (800K~), Prime Pantry (500K~), Beauty (400K~), Gift Cards (150K~), and Luxury Beauty (600K~). We tried to select some categories that were definitively related to each other (Amazon Fashion, Beauty, and Luxury Beauty) as well as a couple that were starkly dissimilar to those in order to be able to see if training the classifier on a subcategory that is related to the subcategory we test on would impact its score and its ability to predict helpfulness accurately. We then trained our model on all five of these categories (sampling 20000 reviews from each correspondingly, each with 10000 reviews voted helpful and 10000 reviews with no votes) and studied how it performed on itself as well as the other categories.
We then trained our logistic regression model on each of these datasets in turn, testing its performance on both the testing data from its own category as well as from the other categories.
Data Analysis
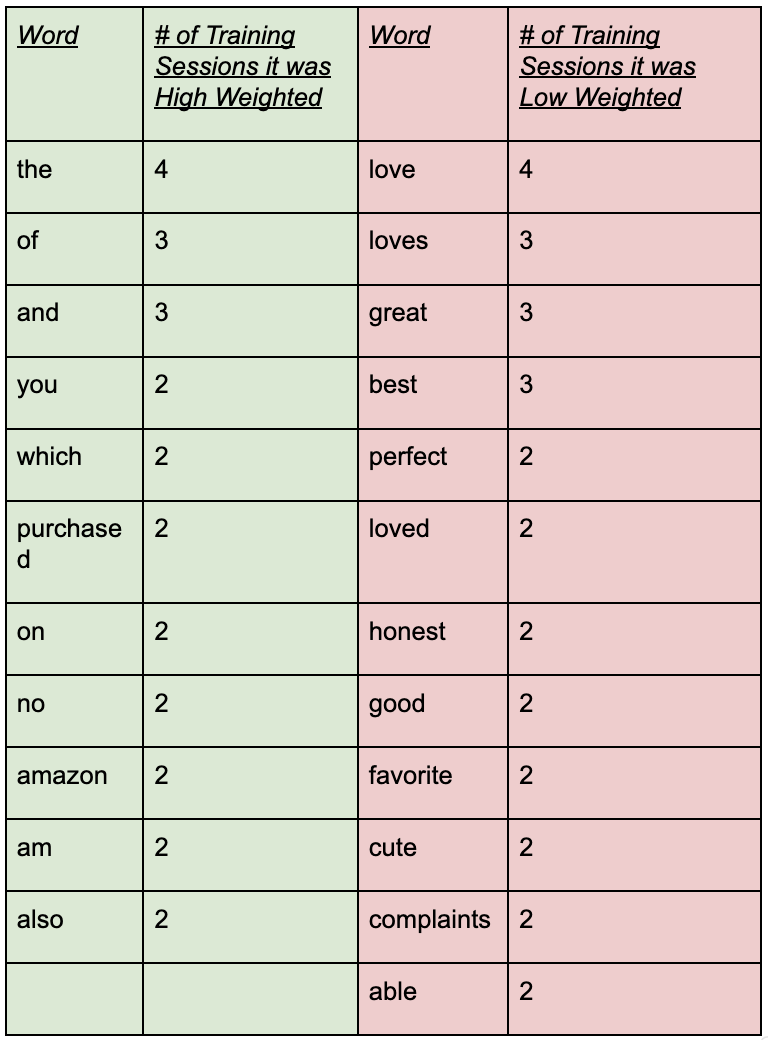
The Bag of Words approach allows us to see the words which are most commonly associated with helpful reviews as well as those associated with unhelpful reviews as the classifier model would learn the weights associated with each featurized vector — highest weighted words are heavily associated with helpfulness, and the contrapositive also applies.
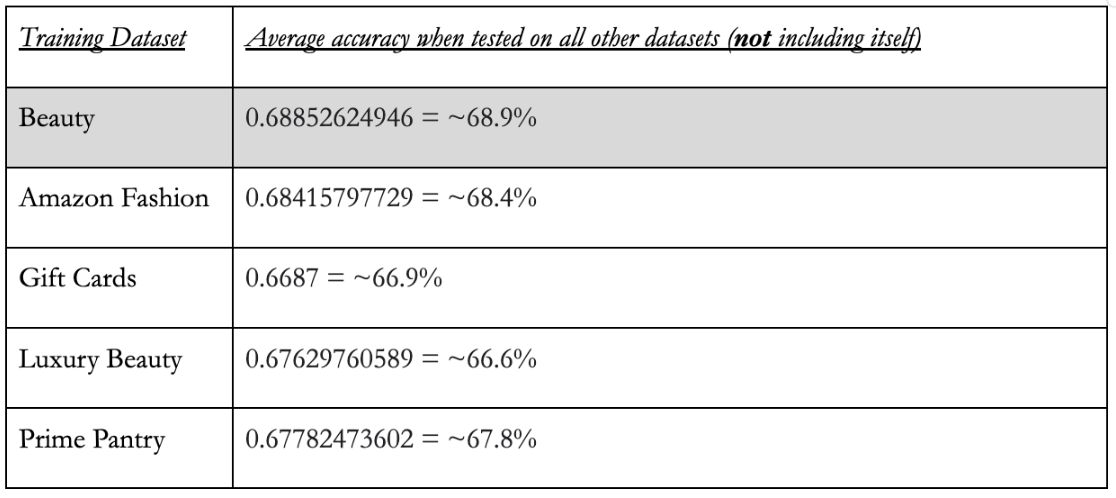
The table on the left shows the words which were weighted heighest and lowest across multiple training sessions, listed in order of number of training sessions. These words are likely to be most strongly associated with helpfulness and unhelpfulness. The table below shows the testing accuracies of the classifier when trained on each dataset.
As can be seen in the list of lowest weighted words, there seems to be an inclination towards words with a overtly positive sentiment. We decided to conduct a rudimentary sentiment analysis on our data based on this observation, manually tagging every word outputted as high or low weighted as having either positive, negative, or neutral sentiment.
As can be seen in the pie charts, lowest weighted words display a much stronger bias towards positive words, which comprise 38.4% of the composite lowest weighted words as opposed to only 1.6% of highest weighted words. A much more significant portion of the highest weighted words were neutral in sentiment, at 87.2% as compared to 53.6% of the lowest weighted words.
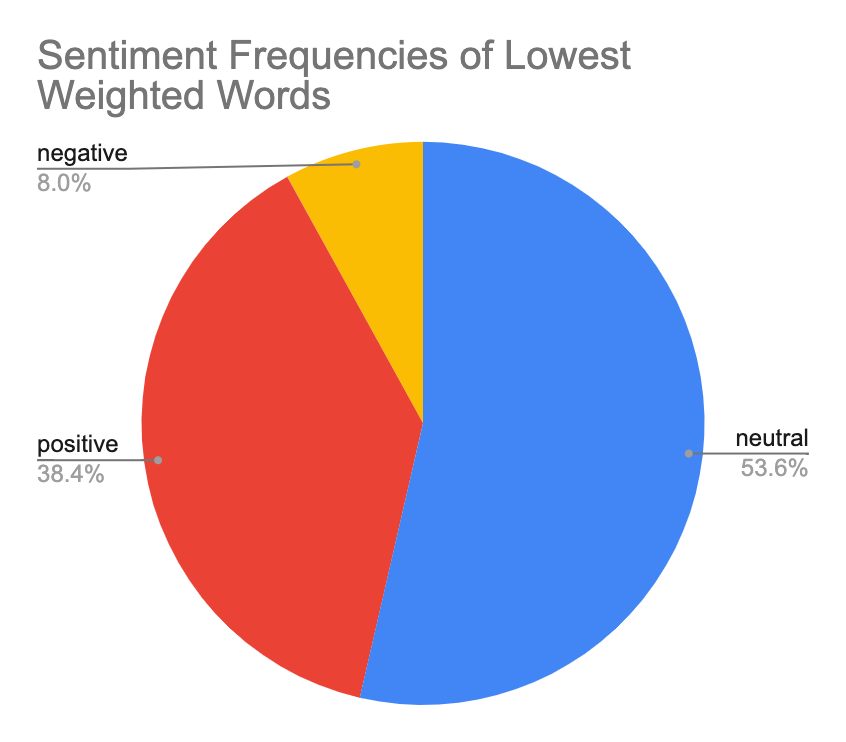
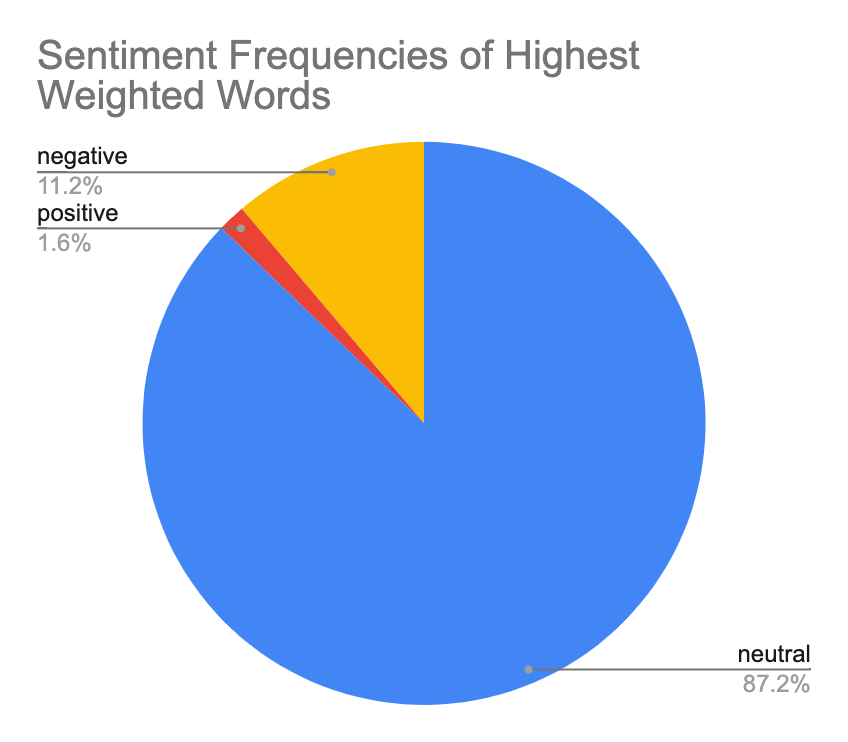
These findings suggest support for the contrapositive of the brilliant-but-cruel hypothesis: based on the small margin, we cannot necessarily conclude that we found negative words to be significantly more frequent among the model’s classification of helpful reviews, but we can say that we found positive words to be significantly more frequent among the model’s classification of reviews that were not evaluated as being helpful.